近年来,大型科技公司利用互联网公开数据训练人工智能模型,并从中获利。然而,随着Reddit和Twitter等平台限制API访问,这种模式变得不可持续。文章提出了一种名为”数据DAO”的解决方案,它允许用户汇集并管理自己的数据,以训练用户拥有的人工智能模型。
文章指出,个人用户仍然可以通过数据隐私法规访问和导出自己的数据,这为创建大型数据集提供了机会。这些数据可以来自各种来源,例如社交媒体平台、个人文档、医疗记录等。通过将这些数据汇集在一起,用户可以创建比任何一家公司都大的数据集,用于训练更强大、更全面的基础模型。
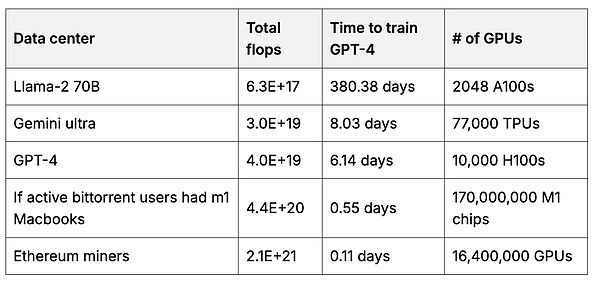
训练模型需要大量的计算资源,但文章认为,用户可以通过个人硬件贡献计算能力,共同训练模型。贡献的用户将共同拥有和管理模型,并根据其贡献获得回报。这将创建一个更公平的AI生态系统,避免由少数大型科技公司垄断。
数据DAO的核心在于去中心化的治理和安全的数据存储。用户贡献数据并获得相应的代币,而数据通过加密方式安全存储,只有在DAO批准的情况下才能访问。这确保了用户对数据的控制权,并避免数据滥用。
文章最后鼓励用户参与数据DAO的建设,认为这是对抗大型科技公司数据垄断,实现真正用户拥有互联网的关键一步。数据DAO不仅有利于用户,也推动了AI发展,使开源AI成为可能,让所有贡献者受益。

